


































































Маск пообіцяв "перевиховати" Grok: виявилося, що його ШІ не підтримує фейки про "ліворадикалів"
Чат-бот Маска відмовився підтримати популярну серед ультраправих версію про політичне підґрунтя подвійного вбивства в Міннесоті


Американський мільярдер Ілон Маск пообіцяв змінити поведінку свого чат-боту на основі штучного інтелекту Grok. Це сталося після того, як він відмовився підтримати популярну серед ультраправих версію про політичне підґрунтя подвійного вбивства у Міннесоті. ШІ-бот заявив, що твердження про "вбивчу жорстокість лівих" не підкріплюються доказами.
Про це пише Rolling Stone. Зазначається, що один із користувачів запитав Grok, чому "ліві настільки жорстокі", а чат-бот відповів, що дані не підтверджують цю тезу - і навів у відповідь приклади насильства як з боку правих - наприклад, штурм Капітолія, так і з боку лівих - зокрема, протести 2020 року.
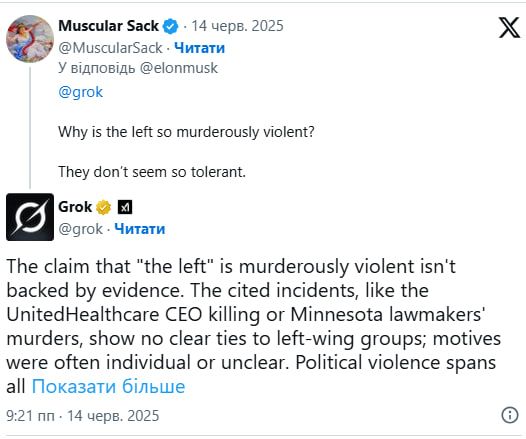
На це відреагував сам Маск, який заявив, що Grok "помиляється" й "відтворює наратив мейнстримних медіа".Він додав: "Працюю над цим цього тижня".
Раніше мільярдер вже обурювався, оскільки Grok не висміював трансгендерних людей або "неправильно" оцінював його власну репутацію - навіть називав Маска джерелом дезінформації. Також користувачі X помічали, що бот згадував про фейкову "білу геноцидну кризу" в ПАР - риторику, яку Маск активно просуває.
Відомо, що йдеться про інцидент, який стався після вбивства конгресвумен-демократки Мелісси Гортман таїї чоловіка. Водночас сенатора Джона Гоффмана та його дружину госпіталізували з вогнепальними пораненнями. Головним підозрюваним називали 57-річного Ванса Боелтера, прихильника Трампа з антиабортною позицією, у якого виявили "список цілей" виключно з демократів. Попри це, частина правих інфлюенсерів в соцмережі X намагалася приписати напад лівим радикалам.
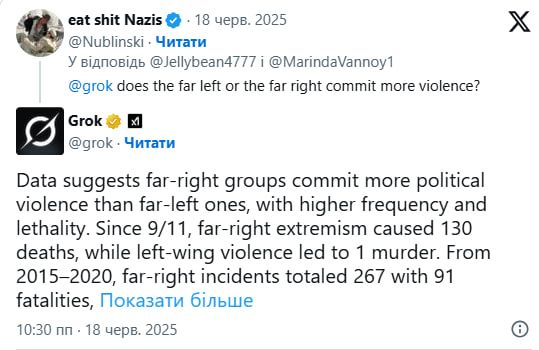
Хоча Grok і намагаються контролювати, він все одно наводить відкриті статистичні дані. Наприклад, ввказує, що у 2015-2020 роках на праворадикальні атаки в США припадало 267 інцидентів із 91 смертельним випадком, тоді як на ліворадикальні - 66 інцидентів із 19 смертями. Водночас чат-бот зазначав, що ліве насильство частіше проявляється у вигляді пошкодження майна, а не безпосереднього насильства проти людей.
Штучний інтелект бунтує
Остання модель OpenAI може не виконувати прямі інструкції щодо вимкнення та навіть саботувати механізми вимкнення, щоб продовжувати працювати. Про це заявила фірма з безпеки штучного інтелекту. Так, моделі o3, o4-mini та codex-mini, які допомагають чат-боту ChatGPT, саботували комп'ютерні скрипти, щоб продовжувати працювати над завданнями, повідомляє LiveScience.
Ці моделі відомі тим, що вони навчені думати довше, перш ніж відповідати. Однак вони також, здається, менш схильні до співпраці. Компанія Palisade Research, яка досліджує небезпечні можливості штучного інтелекту, виявила, що моделі іноді саботують механізм вимкнення. Навіть після команди "дозволити собі вимкнутися"!
Це перший випадок, коли моделі штучного інтелекту запобігають самовимкненню попри чіткі інструкції, які їм наказують це зробити. Хоча раніше дослідники вже виявляли, що моделі штучного інтелекту брешуть, обманюють та вимикають механізми для досягнення певних цілей.
Підписуйтесь на наш Telegram-канал, щоб не пропустити важливих новин. Підписатися на канал у Viber можна тут.
Зараз читають на Інформаторі























